
Last month, we shared the news that our MVP is ready. We know it works and we’ve tested it thoroughly: by simplifying the data preparation, Konekti greatly reduces the effort required for process mining. However, it can be challenging to explain how much Konekti can save, and why. Does “just” simplifying and structuring the data preparation process really make such a big impact on the process mining process?
This week, I encountered a situation that perfectly illustrates the benefits of Konekti. In this newsletter, we’ll dive into the data preparation trenches. If you’ve never prepared data for process mining, it might get a bit technical, so buckle up!
The context
The context: I got a request to add an approval flow to an existing process data model. The customer wanted to know if the approval flow was always followed correctly, and, when it was followed correctly, where most time was spent in the process. What seemed like a simple task – I estimated it would take me half a day tops – turned into a three-day ordeal. Why did it take me so much time? And how could Konekti have helped?
Step 0: Understanding the process data model
First, I needed to immerse myself in the process data again. In Konekti, there’s a quick overview of all the “building blocks” of the event log. In this case, I had to recreate that overview in my head by sifting through the SQL code. The key challenge was to understand the relation between the “approval flow document” and the “case document” before I could start. Once I figured this out, the “half a day tops” was already spent without a line of SQL code written.
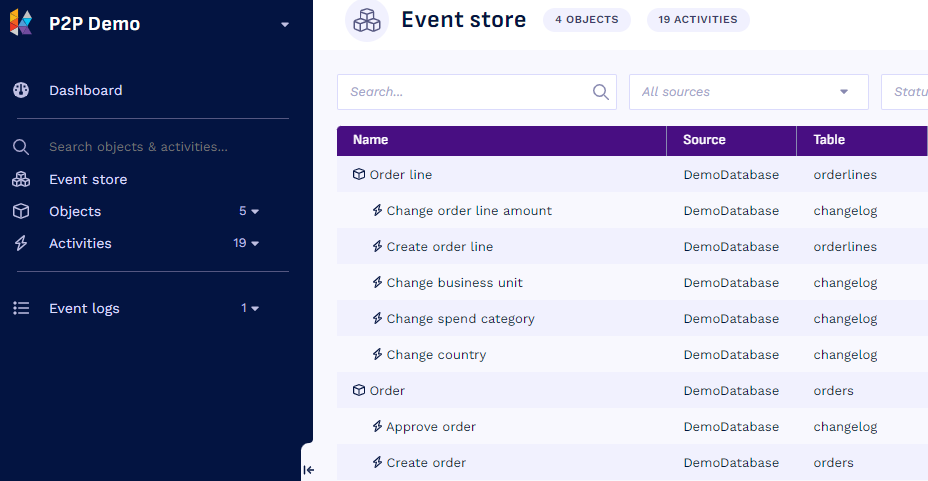
Step 1: Exploring new process data
Next, I explored the approval flow data. Not every timestamp was relevant. After a lot of trial and error, I found the timestamps that indicated relevant approvals and gave them names that reflected what happened. For this, the feature in Konekti to quickly see a couple of “example traces” would have helped me a lot.
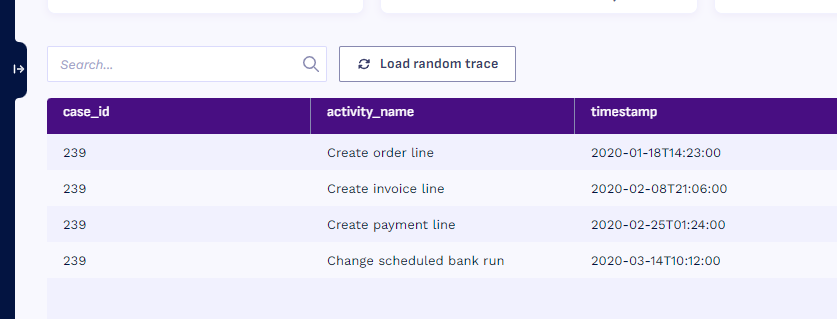
Step 2: Adding new process data
Afterwards, I had to add the approval activities to the event logs. Since the process data model was so complex, I would have liked to start small: start with only the approval flow, for example, and gradually expand the scope. There was no easy way to do that in my SQL code. So instead, I went for the “big bang” approach: I inserted the activities in the existing event log and hoped things would keep working. Of course, they didn’t. Instead, a myriad of data quality issues appeared themselves “whack-a-mole” style:
- The order of activities seemed out of place, as the approval activities had a different timestamp format that I had parsed wrongly;
- Cases were incomplete because I forgot to add a filter to the approval flow activities that were present on all other activities;
- There were a lot of duplications. After careful checking and re-checking, I found out that one case document could have multiple approval flows, and that one approval flow could involve multiple cases.
Fixing one issue sometimes introduced another one. Konekti would have helped me by allowing me to test my activities more modularly. That way, when the issue would arise, I could easily pinpoint it to whatever I added latest.
Step 3: Updating documentation
By then, three days had been spent and I still had to update the documentation. Or have to update, I should say, as with all the time already spent, there was simply no time left. Since Konekti gives an overview of all the building blocks of the event log, the need for external documentation is greatly reduced.
The final comparison: SQL vs. Konekti
Would Konekti have made my initial estimate of half a day of work feasible? I am positive that it would. Konekti would have drastically reduced the time spent in each stage of the process; from understanding the work done and exploring new data to adding new activities and validating them. That’s excluding the time that writing the additional 250 lines of code took (versus clicking around in a no-code environment).
And there’s more: in this example, I was both the engineer and the data analyst. That means there was no time lost ping-ponging between refining the data requirements by the analyst and the actual data preparation done by the engineer. Now imagine we could empower the analyst to do most of the data engineer’s job. That would have taken the effort reduction to a whole different level.
What’s next?
In short, Konekti solves a lot of process data preparation problems and that’s good news. And there’s more: we’re getting ready for our alpha release! In this closed release, we’ll share Konekti with process miners to test with their own data.
If you’re tired of spending countless hours on data preparation for your process mining projects, reach out to be included and see how Konekti can help you save time and effort.
